Abstract
Tilt-rotor aerial robots enable omnidirectional maneuvering through thrust vectoring, but introduce significant control challenges due to the strong coupling between joint and rotor dynamics. While model-based controllers can achieve high motion accuracy under nominal conditions, their robustness and responsiveness often degrade in the presence of disturbances and modeling uncertainties. This work investigates reinforcement learning for omnidirectional aerial motion control on over-actuated tiltable quadrotors that prioritizes robustness and agility. We present a learning-based control framework that enables efficient acquisition of coordinated rotor-joint behaviors for reaching target poses in the $SE(3)$ space. To achieve reliable sim-to-real transfer while preserving motion accuracy, we integrate system identification with minimal and physically consistent domain randomization. Compared with a state-of-the-art NMPC controller, the proposed method achieves comparable six-degree-of-freedom pose tracking accuracy, while demonstrating superior robustness and generalization across diverse tasks, enabling zero-shot deployment on real hardware.
Robot Platform
The Beetle tiltable quadrotor is equipped with four single-DOF tilt joints (DYNAMIXEL XC330 servomotors) and four T-Motor AT2814 brushless rotors. By actively rotating the joint angles, the thrust direction of each rotor can be independently redirected, enabling full 6-DoF actuation in 3D space.
Method
Reinforcement Learning Framework
We formulate the control problem as a Partially Observable MDP (POMDP) and train an actor-critic policy using PPO (Proximal Policy Optimization) in Isaac Sim / Isaac Lab.
- Action space (8-dim): joint position targets $\boldsymbol{q}^{\ast}_j \in \mathbb{R}^4$ + rotor thrust targets $\boldsymbol{f}^{\ast}_r \in \mathbb{R}^4$
- Observation (33-dim): body velocities, relative target pose, current orientation, joint positions, previous actions
- Asymmetric actor-critic: the critic receives privileged rotor thrust and torque signals during training only
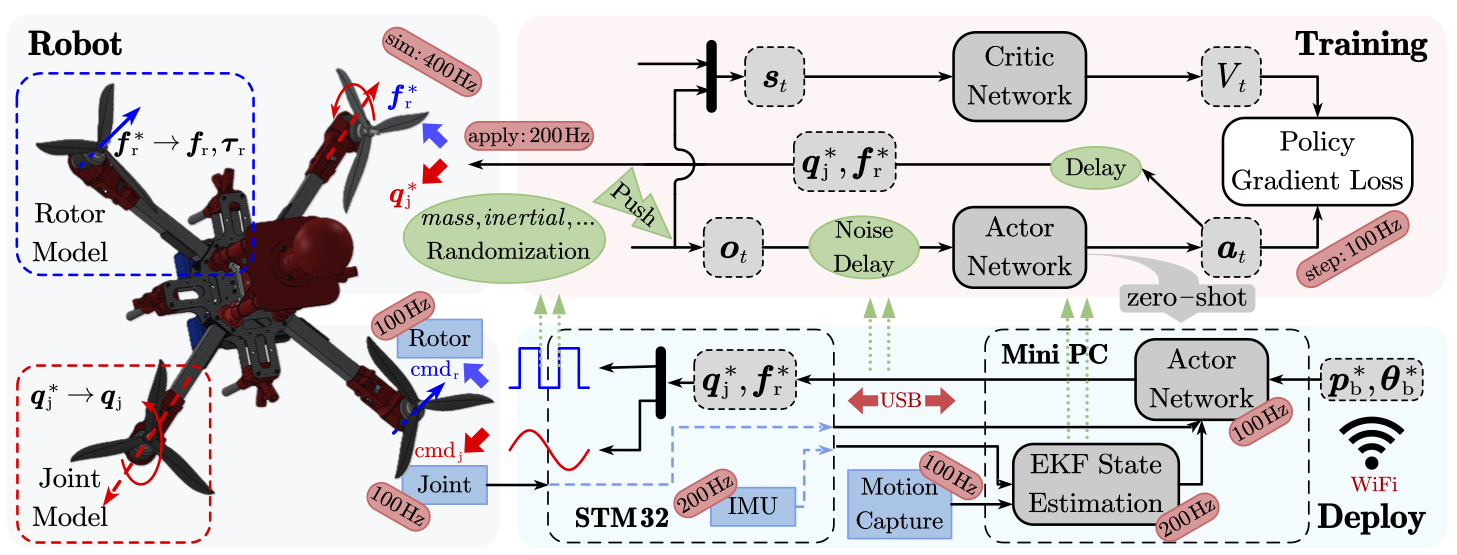
System Identification for Sim-to-Real
A key contribution is physically consistent simulation via system identification:
| Module | Model | Identified From |
|---|---|---|
| Rotor thrust & torque | Polynomial map: $(f, \tau) = g(\text{cmd}, V)$ | 6-axis F/T sensor measurements |
| Joint motor | 2nd-order transfer function $\frac{\omega_n^2}{s^2+2\zeta\omega_n s+\omega_n^2}$ | Sin Wave-response experiments |
| System latency | Communication + estimation delays (3–5 $\mathrm{d}t$) | Timing measurements |
Rather than relying on heavy domain randomization, we randomize only body mass, inertia, and joint offsets, preserving model fidelity while improving robustness.
Experiments
All policies are deployed zero-shot on real hardware against a state-of-the-art NMPC baseline. The RL policy runs at ~0.3 ms per inference step — over 30× faster than NMPC (~10 ms).
Waypoints Hovering
The robot sequentially reaches 5 predefined 6-DoF poses (3 repetitions).
| Target $\boldsymbol{p}^$ [m] / $\boldsymbol{\theta}^$ [°] | RL Pos (m) | RL Ori (°) | NMPC Pos (m) | NMPC Ori (°) |
|---|---|---|---|---|
| [0,0,0.8] / [0,0,0] | 0.114 | 2.59 | 0.026 | 2.64 |
| [1,0,1] / [45,0,0] | 0.060 | 4.35 | 0.074 | 4.37 |
| [0,1,1] / [0,−25,0] | 0.046 | 4.21 | 0.054 | 8.23 |
| [−1,0,1] / [−25,0,0] | 0.074 | 5.56 | 0.028 | 4.74 |
| [0,0,0.8] / [0,0,90] | 0.091 | 4.59 | 0.028 | 1.77 |
| Mean | 0.077 | 4.26 | 0.042 | 4.35 |
RL achieves comparable position accuracy and better overall orientation accuracy. State trajectories reveal more agile behavior: RL peaks at > 2 m/s linear and ≈ 5 rad/s angular velocity during transitions, with faster error convergence.



Disturbance Rejection
The robot holds a fixed hover pose under two external disturbances:
- Continuous wind (fan): RL orientation fluctuation std 0.63° vs NMPC 1.32° — 2× more stable; position std 0.005 m vs 0.028 m.
- Impulsive stick push: RL recovers faster, with sharper but shorter velocity peaks and lower average velocity (0.025 vs 0.033 m/s linear; 0.081 vs 0.092 rad/s angular).


Stable hovering under additional payloads up to 1.0 kg (RL) without re-tuning. Increased payload shifts the vertical ($z$-axis) position offset while orientation accuracy remains stable for both controllers.
Trajectory Tracking (Zero-Shot Generalization)
Although trained only for point-to-point pose reaching, the policy generalizes to tracking a 3D lemniscate with synchronized roll, pitch, and yaw modulation — zero additional training.
- Mean position error: 0.16 m (RL) vs 0.05 m (NMPC)
- Mean orientation error: 8.06° (RL) vs 5.19° (NMPC)
- Comparable tracking stability: position error std 0.04 vs 0.02 m; orientation error std 2.45° vs 2.46°
The RL policy behaves as a low-level feedback motion controller, enabling robust and stable tracking of dynamic trajectories well beyond its original training scope.
![]()
![]()